Illusory Attacks: Detectability Matters in Adversarial Attacks on Sequential Decision-Makers
Abstract
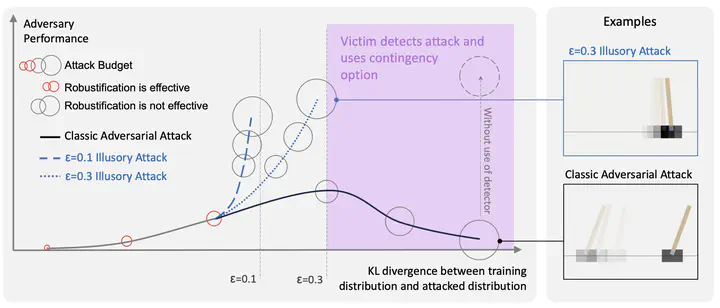
Autonomous agents deployed in the real world need to be robust against adversarial attacks on sensory inputs. Robustifying agent policies requires anticipating the strongest attacks possible. We demonstrate that existing observation-space attacks on reinforcement learning agents have a common weakness; while effective, their lack of information-theoretic detectability constraints makes them detectable using automated means or human inspection. Detectability is undesirable to adversaries as it may trigger security escalations. We introduce illusory attacks, a novel form of adversarial attack on sequential decision-makers that is both effective and of bounded statistical detectability. We propose a novel dual ascent algorithm to learn such attacks end-to-end. Compared to existing attacks, we empirically find illusory attacks to be significantly harder to detect with automated methods, and a small study with human subjects suggests they are similarly harder to detect for humans. Our findings suggest the need for better anomaly detectors, as well as effective hardware and system-level defenses.
Adel Bibi
Senior Researcher in Machine Learning and R&D Distinguished Advisor
My research interests include machine learning, computer vision, and optimization.