Abstract
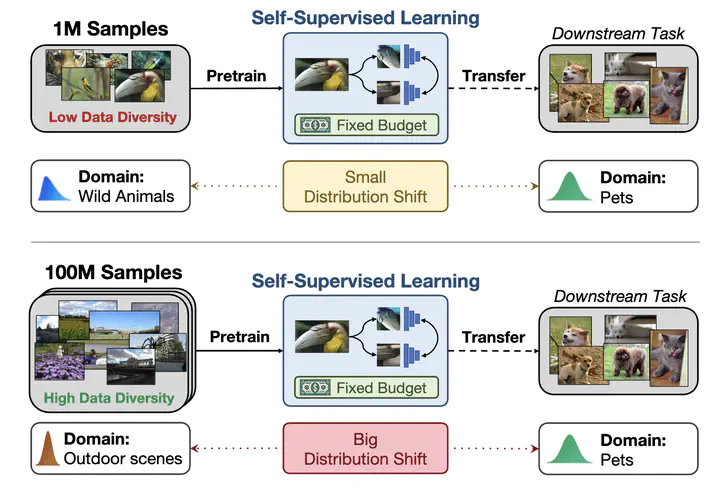
We explore the impact of training with more diverse datasets, characterized by the number of unique samples, on the performance of self-supervised learning (SSL) under a fixed computational budget. Our findings consistently demonstrate that increasing pretraining data diversity enhances SSL performance, albeit only when the distribution distance to the downstream data is minimal. Notably, even with an exceptionally large pretraining data diversity achieved through methods like web crawling or diffusion-generated data, among other ways, the distribution shift remains a challenge. Our experiments are comprehensive with seven SSL methods using large-scale datasets such as ImageNet and YFCC100M amounting to over 200 GPU days.
Adel Bibi
Senior Researcher in Machine Learning and R&D Distinguished Advisor
My research interests include machine learning, computer vision, and optimization.